


|
Last updated on Monday 28th of February 2022 08:52:48 PM Deduplication at block levelWhat is deduplication? Please note that this post is relative to old deprecated software ©XSIBackup-Classic. Some facts herein contained may still be applicable to more recent versions though. Please note that this post is relative to old deprecated software ©XSIBackup-Classic. Some facts herein contained may still be applicable to more recent versions though.
For new instalations please use new ©XSIBackup which is far more advanced than ©XSIBackup-Classic. Data deduplication is an old technology that never really succeded due to the rapid development of new technologies that allowed to increase the size of the storage devices and lowered their price at the same time. Data deduplication consists basically in storing every piece of data only once. There exists deduplication at file level; if tomorrow's backup has only a few file changes, the deduplication engine won't copy the preexisting ones, but will represent them as a pointer to the single copy of the file. Deduplication at file level is different to a classic differential backup in an important aspect, as it can generate backup structures that allow us to move in time to access a file configuration at a given point in time, but using almost the same hard disk space as a single backup copy. File level deduplication has a big drawback when we want to backup a few very big files, like a database or a bunch of virtual machines. Changing just one byte of information in a virtual machine would mark the whole file (that could be hundreds or thousands of gigabytes big) to be updated in the subsequent backup cycle, loosing the advantage given by file level deduplication. 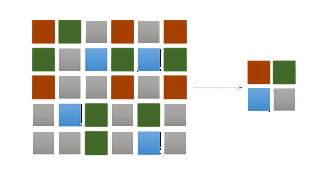
To solve the problem posed in the previous paragraph we can use block level deduplication. Blocks are the logical constitutive elements that compound the data stored in any hard disk and that are usually an integer multiple of the sector size of the physical media that stores that info. Block level deduplication allows a new backup to record only changed blocks and store the rest as pointers to the non changed ones. To say it in a different fashion; block level deduplication stores each individual block only once. This is an ideal aproach to store big files that share many blocks, like virtual machines hard disks, as many of the files in any given virtual machine belong to the operating system or installed programs and only part of them will be user files, and even among the user files only a part of them will change from one backup cycle to the next. Thus a block level deduplication system is a very interesting storage media to combine with any virtualization system, not only for backups but even for the storage of the virtual machine disks. The speed of a backup process can be increased considerably depending on the characteristics of the data itself and the deduplication system tweaks. Take on account that if we set a block size of 4 mb. per instance, the data will be compared by means of its checksum, and it will be many times smaller than the 4 mb., reducing thus the amount of data to transfer. In the last years due to, overall the rapid development of virtualization technologies, deduplication has re-emerged as a way to drastically reduce the amount of required storage. At 33HOPS we apply deduplication at block level for various tasks related to the design and maintenance of virtualized environments. Read too: How to use deduplication resources effectively Extend information without any compromise from your part |


|