
|
Last updated on Monday 28th of February 2022 08:52:48 PM Deduplication softwareApproach to deduplication, software that implements it Please note that this post is relative to old deprecated software ©XSIBackup-Classic. Some facts herein contained may still be applicable to more recent versions though. Please note that this post is relative to old deprecated software ©XSIBackup-Classic. Some facts herein contained may still be applicable to more recent versions though.
For new instalations please use new ©XSIBackup which is far more advanced than ©XSIBackup-Classic. Deduplication series:
Deduplication is a very interesting technology that has re-emerged in the last years due to the widespread of different virtualization technologies and the usefullness of this technology in these contexts. There are basically two deduplication technologies from a conceptual point of view: file level deduplication and block level deduplication, we'll focus on the latter, as it is the type of technology that will help us to increase our productivity and lower our costs. The so called "zone deduplication" could conceptually be included into block level deduplication. Block level deduplication helps us by storing each individual data block in a hard disk only once. If that block is present many times accross our data, becose it is a chunk of a Windows DLL per instance, instead of storing it ten times, once per each of our ten eventual Windows Server virtual machines, we'll store it only once and use only one tenth of the space we would need to use in a non deduplicated scenario. 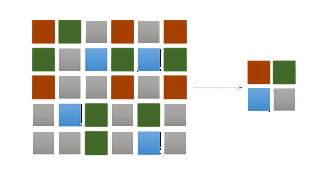
Sounds great, and it is great, but, how does it work?, and which are the drawbacks (there had to be some). Well, the mechanism that is used to know if we already have a particular block in our collection of already stored chunks is hashing. A hash is a sort of label that will uniquely identify a chunk of data. There are many different hashing algorithms, like MD4, MD5, SHA-1, etc.... In absolute terms a hash cannot represent a collection of ones and zeroes uniquely, if the number of possible combinations in the hash length is less than the number of possible combinations in the binary sequence. In other words, a sequence of ones and zeroes can only be uniquely represented by itself. But thanks to our knowledge of basic mathematical principles, like Dirichlet's "Pigeon hole principle" and their, not so basic implications, we know we have the chance to represent a piece of binary data by its hash. How?: we can treat the problem from a probabilistic point of view, and know with almost absolute certainty that a given hash represents our block. We can caliber the degree of certainty by modifying the hash length or its deepness, in such way that we feel comfortable enough with the probability of a collision. A collision is the probability that two different blocks (different sequences of ones and zeroes) get represented by the same hash. We are talking about astronomical figures, in most cases the probability of a collision will be less than that of a meteor landing in your toilet. Nowadays we have algorithms and CPUs strong and fast enough respectively to allow to build a deduplication system reliable enough to be put into a production state. Well, great, we have the data and we have the hashing algorithm. We should be storing them all toghether in pairs (block+hash) somewhere. That place should allow us to check as fast as possible if we already have a given hash, and thus a given block. Those systems are called databases, but we cannot rely on one of the most well known database systems like MySQL, SQL Server, Oracle, etc..., mainly because they are not fast enough to serve our purposes in a working filesystem, we need real time performance. There are some special database systems that have been designed for speed and not so much to build complex relationships between the data sets. They are called key/value databases, and will do the job we need to store our blocks and their hashes. Well, well, well, lets go on with our maieutics: we have the data, we have a great hashing algorithm and we have a really fast key/value database system. What now?, the idea is simple, right?, every time that a block of data is to be written to our hard disk, it should be hashed and the hash should be sought in the key/value database, if we find it, we could asume the block of data that is stored along with the hash in the database is the very same block of data that we are trying to write to disk, and thus we should simply create a link to that block instead of writing it again to disk, as we would do in a non deduplicated system. If on the contrary, the block is not in our database, we would simply store it for the first time. Now we got the concept!, there's only a million miles of C code to type into our computer. But wait, I am probably not the first to think about the matter, so there migth already be some tools out there that do the job. In fact there are many tools that deduplicate data at block level, but first we must think about what our needs are. If we want the deduplication feature only for backup purposes, we might not need a full deduplicated file system, and a simpler tool that is able to store the data in its own structures might be enough, the only downside will be the need of this tool to extract the data to a regular filesystem. If for whatever reason we need the data to be stored in a typical filesystem structure, to be able to access it in real time, then we will need to go for a deduplicated filesystem. Some deduplication systems:
Now we have a little overview of what exists out there. But, what to choose?. First we must take into account some general considerations: if we want our deduplicated storage to store data for backup purposes, then ZBackup might be enough for you, with the commented downside of needing it to recover the backed up files. If you want to be able to recover the files straight from a filesystem, then you need any of the other tools. If you have something more ambitious in mind, and want to use the filesystem to store running virtual machines, then you need something well proven and resilient enough to behave like a regular filesystem. In that case ZFS, OpenDedup or Windows Server 2012 (or above) are your best choice, although you'll have to pay the cost in terms of hardware requirements, as you will need a lot more CPU and memory. FUSE: What is FUSE, and why do I dedicate a full paragraph to it?. FUSE stands for Filesystem in User Space. It is a bridge layer between the kernel and the user space that allows to program filesystems without the need to edit the kernel code. Why is it important to know what is underneath the tools we use?, well, one of the main differences between a piece of code running in the kernel space or in user space is memory protection. Thus, programs running in the kernel memory space, like drivers, regular filesystems, I/O, etc... are a lot more stable than programs running in user space, like regular applications. Also the way they use memory and the way it is managed is more efficient than in userspace. In other words, a program running in user space is more likely to hang and will be slower than that running in the kernel reserved space. There is a nice set of mail posts and responses where Linus Torvalds expresses his skepticism in regards to filesystems built on top of FUSE. You should read those thoughts to build your own intelectual position in regards to FUSE filesystems. http://www.spinics.net/lists/linux-fsdevel/msg46078.html In any case, many production-proven FUSE filesystem implementations are out there in the market and they are doing a good job. ZFS and SDFS (opendedup.org) are built on top of FUSE, so, should I use them?, are they safe?. Well, the answer is clear: YES, you can use them and they are safe enough as the base for your files, just as long as you understand how they work and what you can expect from them. I'll put the matter upside down and use the old "Reductio ad Absurdum" technique, or Reduction to Absurdity if you prefer it in plain English: Let's say that you run a small system with a limited budget, but you still want to take advantage of deduplication, mainly becose it will save you a lot of money and will allow you to store more VM in the same storage room. So, you are told about ZFS and its advantages and install it in a server to act as a datastore for your ESXi virtual machines. Let's say this server is something powerful enough to act as a NAS unit (8 gb. of RAM on an i5 Intel CPU). You will soon discover that as a few users start to connect to any of the VMs, the CPU usage on your ZFS file server starts to grow rapidly, and that memory consumption grows wild. In a few minutes your users will start complaining that opening a 100 kb Word file takes 5 minutes, and that they cannot work in such way. Does this mean ZFS is useless?, of course not, it simply means that the hardware requirements of ZFS are far beyond your posibilities, and that if you make use of deduplication, these requirements will be specially high. We have explained before how block level deduplication works, so it's easy to understand why these requirements are so high. If you take on account that such systems try to maximize memory use to improve speeds and latencies, you'll end up with a 64 gb RAM and 16 core system just to give service to a small department. So, what are the advantages then?: there are many, if you comprehend what you can get out of it and what not. Let's say that you need to run 7 Windows and 5 Linux servers in an ESXi box, I used ESXi for my example because it's the most used hypervisor out there, but you can think of your favourite virtualization system. You don't have the budget to buy anything better than that i5 with 8 gb. of RAM mentioned before... |


|
Login • Available in: 