


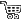
|
Last updated on Friday 12th of May 2023 01:10:54 PM ©ESXi Snapshot Errors and Solutions.What are snapshots, how to use them issues and fix procedure.This post was fairly old and needed some revision. The same basic principles still apply to snapshots though, they have not changed from a conceptual point of view.One of the most common sources of support requests from part of our registered users is problems having to do with snapshots: creation, deletion, quiescing, etc... • Can't create snapshot • Can't delete snapshot • How to fix issues related to snapshots What is a snapshot?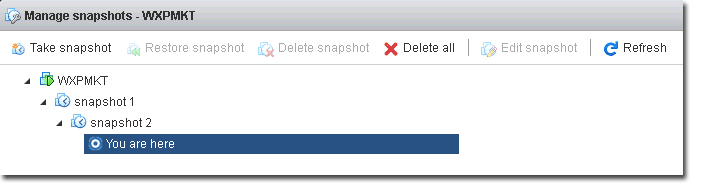
The way they work varies depending on the technology used, although the concept always implies some kind of discontinuity in the stored data that allows some kind of upper level manipulation from part of the sys admin. The concept exists associated with multiple storage abstraction systems, like: LVM, LVM2, ©ESXi, ZFS File System, etc... Snapshots in ©VMware ©ESXi are a powerful feature that allows you to take a point-in-time copy of a virtual machine's disk. Snapshots can be very useful for creating backups, testing software updates, and rolling back changes, among other things. However, there are also some common issues that can arise when using snapshots. Here are some of the most common ones: Snapshot size: Snapshots can quickly grow in size if they are left for too long or if the virtual machine continues to write to the disk. This can cause performance issues and can even lead to running out of disk space. Long consolidation times: When you delete a snapshot, the changes made to the virtual machine's disk since the snapshot was taken need to be merged back into the original disk. This process is called consolidation and can take a long time if there are many changes or if the snapshot is large. Performance degradation: The more snapshots a virtual machine has, the more overhead there is in managing them. This can lead to slower performance of the virtual machine, especially if the snapshots are active. Snapshot "chain": Snapshots are created as a chain of files, with each snapshot building on the previous one. If a snapshot in the chain becomes corrupt or is deleted accidentally, the entire chain can become unusable. Data consistency: Snapshots can affect data consistency, especially if applications are writing to the disk. If a snapshot is taken while an application is performing a write operation, the resulting snapshot may be inconsistent or incomplete. To avoid these issues, it is important to use snapshots judiciously and to manage them properly. This includes monitoring their size, keeping the number of snapshots to a minimum, and deleting them as soon as they are no longer needed. It is also important to use backup software that is aware of snapshots and can handle them properly. In this post we will cover snapshots in an ©ESXi environment. In the ©VMWare ©ESXi Hypervisor, snapshots are temporal subsets of blocks generated from some moment in time (the time you take the snapshot) which are stored in separate virtual disk files. They can be read for the data they contain and they can be written to if the VM is sitting on top of one. You can later decide whether you want to delete or discard that data. They are the best way to accomplish a hot consistent ©VMWare backup, as the snapshot mechanism already includes the logic to generate consistent discontinuity in the I/O stream. Deleting a snapshot in the ©ESXi jargon means to commit that data to the base disk (where the permanent virtual disk data resides) when you are positioned some point after the snapshot file representation in the chain of snapshots. On the other hand when you delete a snapshot which exists past the point where you are in the chain, the snapshot data is discarded. 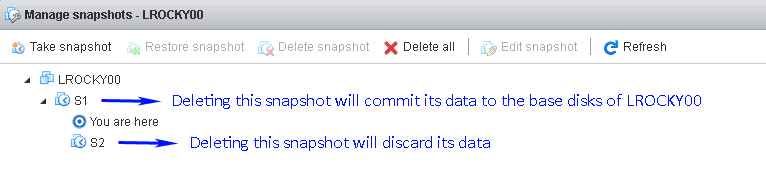
You need to visualize this from the view of the snapshot manager. When you "restore" some snapshot you revert your VM to some state, that is: you travel to some point in time in the history of your VM when you generated that snapshot file. Again the snapshot related terminology contradicts the implied semantics. You can chain snapshots, up to 128 of them (if I remember right), although you will most probably never reach that theoretical limit, as the VMs slow down as you add more, and in most hardware just a few will render the VM virtually unusable. One given snapshot depends on the previous ones, as data stored in a lapse of time alone has no sense on its own. You may want to take some time to think about that fact, you will find it's obvious though. Snapshots are a conceptual abstraction that allows to accumulate temporal subsets of data. Whatever you use them for is up to you. There exist some common predefined uses which gives them meaning 99% of the times. What are ©ESXi snapshots useful for?The most common use of snapshots is to be able to revert some given VM to a previous state. This is very useful in test scenarios, per instance, when you want to try some new version of something or install some software update, but you want to make sure you can revert the guest to the previous state should something go wrong.In an ©ESXi backup and recovery scenario, snapshots in a VM which has been backed up can be used to revert the backup to any of the restore points the snapshots offer. Problems with backup snapshotsYou may encounter different errors related to snapshot creation and deletion, nonetheless they can be summarized in:- Can't create snapshot. - Can't delete snapshot. This might seem to be an oversimplified explanation, but it's enough by now. I want to break a lance in favor of ©VMWare in this case, as the snapshot feature works very well. When you hit some issue having to do with snapshots it's usually related to something not working well: hardware failure, disk is full, or to something you aren't doing right: mixed HW or VMFS versions, missing files or misconfigured services in case of quiesced snapshots. Can't create a snapshotWhen a snapshot can't be created, it's usually due to something preventing it from happening. You should get used to scan the VM log files and also the host level log files at /scratch/log in search of hints. The most common situations are:- Lack of space in virtual disk volumes. - Lack of space in the main /tmp dir - Lack of space in the /scratch partition - Service in the guest OS refusing to be quiesced and raising an error from ©VMWare Tools The commands below will spit any errors found in the host general log dir at /scratch/log and in the VM logs. cat /scratch/log/*.log | grep -i "error"
cat /vmfs/volumes/
This other commands will detect whether some partition or virtual file system utilization is above 90%. Please note that only those closer to 100% utilization will represent a real problem. df -h | tail +2 | awk '{sub("%", "");if($5 > 90){print $0}}'
vdf -h | grep -iv "^ramdisk" | awk '{sub("%", "");if($5 > 90){print $0}}'
The above will allow you to know if you are lacking space in some volume or file system. If your problem is not related to low space availability, then it's more likely due to trying to quiesce the guest OS. Should that be the case, you should have found some related errors in your logs by now. You have different ways to address the issue when it comes to quiescing your guest. First of all determine if you really need quiescing. What is quiescing? To understand snapshots you need to think about how I/O works in a given OS. We don't need to get into the nitty gritty details of how the OS and filesystem work, just comprehending that it is a complex system with many parts involved and that it's not the same a file server than a server hosting services which are constantly writing data to the guest's disks, such as some database server. A file server is easy to handle, the file system itself takes care to write files consistently. If you take the snapshot while some file is being written to disk, it will just not appear in your guest file system. Nonetheless, when you host a busy database, e-mail or similar type of service, the pending I/O operations need to be flushed to disk before the snapshot can actually be taken. If that would not happen, the database files could get corrupted with partially written data. This is, to some extent, a similar scenario to that of a power cycle, in which the database service needs to be shutdown in a controlled way to make sure that data is written consistently before shutting the service down. The main difference is that a quiesce operation will stop the service just the time required to take the snapshot, which will usually cause a short glitch in the service functioning. If the quiescing process goes well, users will just notice a short delay, usually shorter than a second. ©VMWare Tools ©VMWare Tools acts as an intermediary service that requests the quiescing operation and confirms it to the hypervisor. Thus, you need ©VMWare Tools installed, as well as any other additional auxiliary service that might be necessary to perform the controlled stop. Please, note that ©Windows Servers running SQL Server will need, not only ©VMWare Tools, but also Virtual Disk VSS Service plus some additional components depending on the version you are running. Some other database servers, specially some older versions, may not be eligible to be quiesced. In these cases there are some workarounds that we'll comment ahead. Can't delete a snapshotBefore saying anything else about this theme as well as the opposite operation (creating a snapshot) you should clearly draw a dividing line in your mind in regards to snapshots to clearly differentiate between quiesced and non-quiesced snapshots.We treat quiescing specific issues at the end of this post. By now we have just introduced what quiescing is and we are still addressing problems that affect snapshots in general. You have two levels to differentiate in dealing with snapshot issues: those that affect all snapshots, which should be considered gross issues generally having to do with lack of space or some misconfiguration and issues affecting quiesced snapshots, which normally have to do with active services running in the guests like DBs and the need to stop them gracefully before taking the snapshot. Troubleshooting quiescing issues is somewhat different to not being able to create a snapshot at all. Some of the causes for the latter are related to lack of space. We won't comment that any further, as the procedure to detect that situation is the same as above. As also commented above, deleting a snapshot consists in integrating the data into the base disk or discarding it permanently, depending on where you are positioned in the chain of snapshots. The base disk can be a -flat.vmdk file or another snapshot, depending on how many of them you have piled up. Possible causes of one or more snapshots not being deleted are: - Lack of space in any of the above mentioned volumes or virtual FSs. - Incompatibility between VMFS or VM Hardware Versions - Missing or corrupt associated files. - Other issues, buggy behaviours from part of ©ESXi. Incompatibility issues To create or delete a snapshot you need the snapshots in the chain to be compatible between them and with the Hardware Versions your ©ESXi server supports. Per instance, when you move some differential data between ©ESXi servers, like in the case of OneDiff snapshots, you need the hardware versions of the VM and the underlying VMFS versions to be the same, or, at a minimum, the VMFS versions must coincide and the hardware version of the originating VM must be compatible with the target server. You can copy some VM from ©ESXi 5.5 to 6.5 and make it work, but not the other way around if the HW version of the VM running in ©ESXi 6.5 is not supported by 5.5, otherwise you will receive an error. The same applies when you move a VM containing snapshots from one server to another. Your snapshots will not work unless your VMFS version is the same and compatibility between the source and target servers is met for your VM. As explained, some VM with Hardware Version 8 will work in ©ESXi 5.5 and also if you move it to ©ESXi 6.7, but some VM with HW version 11 will not work if you move it to ©ESXi 5.5. You can check compatibility in the link below: List of compatible ©ESXi and Virtual Hardware versions. Missing or corrupt files A snapshot is composed by multiple files. The .vmsd file contains information on how many snapshots are attached to a VM and how they are related to each other, namely: the hierarchy and relationship order in the snapshot chain. When this file gets damaged ©ESXi cannot figure out how to integrate the data into the base disks, the VM might even be working fine, still the snapshot deletion fails. Renaming (always consider rename an alternative to delete) the broken .vmsd file and creating a new snapshot generates a new .vmsd file, this can be used to repair some broken chains of snapshots when the .vmsd file contains wrong information. When it is damaged, another approach to recover the data could be to just clone the VM from the desired snapshot .vmdk file using vmkfstools, this would generate a consolidated -flat.vmdk file with all data coalesced into a single virtual disk. Other issues A general system error occurred There is a problem that arises from time to time in a given system, you cannot create snapshots, nor delete any pre-existing one, the event log shows A general system error occurred. Sometimes this problem persists even after discarding some snapshot data files manually, even after rebuilding data from a chain of snapshots as explained in the following paragraph. This drives users crazy and seems impossible to fix. We have been able to reproduce this problem, that has to be considered an ©ESXi bug, in 5.X and 6.X systems. For some unknown reason, the VM regenerates a .vmsd file with invalid information, even after deleting all the snapshot files manually, including the .vmsd file itself. The bad .vmsd file that reproduces itself without any apparent reason, contains information about a snapshot that does not exist any more. It does not matter how many times you turn the VM off and delete the .vmsd file, the wrong information reappears over and over. Even if you clone the VM from the topmost snapshot, the wrong information keeps on being thrown into the .vmsd file. It is clearly not something in the ESXi host itself, as unregistering the VM and registering it again with a different id does not help the problem. Thus, it has to be something related to VMWare Tools. Solution: We have found that deleting the .vmsd file once the VM has been turned on and the wrong .vmsd file has been recreated, allows to create a new snapshot. From this point on, the problem seems to get resolved. As some of the snapshot descriptor files can be damaged if this problem affects you, the best way to give remedy to it is to clone from the topmost snapshot, switch the newly created VM on, delete the .vmsd file and take a new snapshot. How to fix issues related to snapshots
We will limit this paragraph to explaining how to fix a broken chain of snapshots, as not being able to create one is limited to identifying the cause, but there's nothing that has to be undone. In case of a broken chain of already existing snapshots, you not only need to find the cause and fix it, but you need a way to consolidate your data back into the base disks, be them some -flat.vmdk files or some other snapshot. First of all: identify the issue, query your logs for clues. Check whether some inconsistency exists that is preventing the snapshot deletion from taking place, like some previous Onediff differential operation or the VM having been moved from one host to another. • Turn the VM off and try to consolidate the snapshot chain. • Delete the .vmsd file and try to create a new snapshot on top of the previous ones. The .vmsd file should be regenerated • Unregister the VM and register it again. • Restart the host service or reboot the host, the latter is always more decisive. If the problem persists, you will have to decide whether discarding the information in the snapshot files or try consolidating the data in a new -flat.vmdk disk by running a vmkfstools clone operation. Rebuild the VM data from the chain of snapshots If you are lucky, the consolidation will work and you will be able to commit those snapshots to the base vmdk files. If you aren't, then you will need to rebuild everything into a consolidated base vmdk file, or a set of them. If you have more than one virtual disk in that given VM. By doing that, you will loose your snapshots, but will save your data. This means you won't be able to go back to a previous state of the VM, but at least you will keep your valuable data. At this point you should consider yourself fortunate that you can do so with some minor hassle. If your set of snapshots is in a good state, then you may decide the snapshot from which you will consolidate the broken VM, and thus the point in time to which you will revert it. In any case, this procedure is more complex than a simpler full consolidation starting with the topmost snapshot, specially if you want to preserve the remaining snapshots in the chain. In this post we will cover the simplest scenario and will recover the VM from the topmost snapshot available. If you want to recover from an earlier one, just follow the same procedure, but from a previous snapshot in the chain, and discard the rest of the data. It is the exact same procedure that is described above around coalescing the data to the base disk or discarding it depending on what your position in the chain of snapshots is, but instead of performing the action from the snapshot manager in the GUI, you do so in the command line. The good part is that you can rebuild your VM nay times from different snapshots until you get to the desired point in time for your VM, as it will generate a new independent file. To do that you will need to use vmkfstools in the following way: find the topmost snapshot (or the one you want) .vmdk file, it will be something like yourVM_disk1-00000N.vmdk, you will find one -00000N.vmdk file per disk in the VM, if you only have one disk, there will only be a set of snapshot .vmdk files. Locate them all and clone each one of them (from the highest N present) by using vmkfstools this way:
vmkfstools -i yourVM_disk1-00000N.vmdk /vmfs/volumes/datastore2/yourVM/yourVM_disk1.vmdk -d thin
This will create a new .vmdk file descriptor plus the associated -flat.vmdk file containing all the consolidated information from the base disk plus all the snapshots in the chain. Next step is to copy the .vmx file to the destination dir "/vmfs/volumes/datastore2/yourVM" in the example) and edit it by using vi editor to reflect the new paths to each disk. That is all, you can switch your VM on, and if all steps were taken adequately, you will have a new sanitized VM. Discard the information in the snapshot files This is the last resort and consists in renouncing to the information contained in the snapshots and reverting the VM back to the state it was previous to taking them. Needless to say that the above procedure applies to any snapshot in a chain, that is: you can clone a VM from any of its snapshot .vmdk files. Thus you can try to recover the data from any of the intermediate points before getting down to the base -flat.vmdk file. Manually discarding a snapshot consists in editing the .vmx file and pointing the virtual disks to the previous snapshot in a chain. In case you only have a snapshot or you want to discard all snapshot files, you point the .vmx file to the base .vmdk disk, namely: the one that does not contain any -00000N string in its name and has a -flat.vmdk counterpart. Needless to say you must be careful when you discard some snapshot and you must delete or rename the snapshot files you don't want to keep to avoid them interfering in your snapshot chain later on. Some useful notes on quiescingQuiescing issues are always relative to the OS, version, running services and many other circumstances. Still, the most important thing is to comprehend what it is and how to deal with it. We have covered this in many posts and articles before, I will offer an excerpt here:Some services like databases, specially if they are busy systems, require that their pages are fully written to disk to be 100% consistent. Let's say you have a series of SQL statements that add some data to your DB. If the snapshot is taken in the middle of some I/O operation to disk, the cut point may not include the final statements and the closing bytes of the transaction. This would cause that restoring the VM backup would return some corrupted DB message from part of the DB system when trying to turn the database service on again. Do not panic. When someone uses the word corruption one tends to think of some fully corrupted data from the beginning to the end. In case of non-quiesced snapshots, what you have is some unclosed page written to the DB. Fixing it is easy, it just requires to run some standard repair tool that will get rid of the partially written data. Still, that is a hassle and in case of big DBs might take some valuable time. This is where quiescing comes in handy. Quiescing is a concept, it may involve many different pieces of software depending on the OS and DB system you are using. Microsoft OSs are in general trickier to quiesce than Linux. You will usually need the Virtual disk service running plus Volume Shadow Copy service in automatic mode and, off course, the latest version of VMWare Tools correctly installed. The checklist below will do it most of the times: Virtual Disk service is started and startup type is Automatic.
VMware snapshot provider service is stopped and disabled.
VMware Tools services are running.
Ensure that Volume Shadow Copy service start up type is Automatic
There are additional helper services for MS SQL Server and Exchange that may be required in your case. But the above are just the steps to take to get ©VMWare (c)ESXi to quiesce your system without errors. You need to comprehend what's behind this, which in the end is very simple and easy to understand. What the different quiescing mechanisms do is to put the DB system in Read Only mode, flush any pending DB I/O buffers (namely: write any pending data to disk) and take the snapshot while keeping any new data on hold. When the snapshot is finally taken the DB system is put back in RW mode. This usually requires just some seconds to complete 1-5 seconds from our own experience. During that time the DB system is still available for reading, thus there's only a short glitch for writes which can easily be addressed from the application layer by just delaying some write when you get a RO message from the database server. Now, the thing is how to accomplish the above for every database system and OS. As said there exist some helper services that will do that for you and may add some more sophisticated logic that will minimize the downtime, still there will always be some minimal downtime. As stated, this can be addressed from the application layer. What if I have some DB system that does not offer some helper service to accomplish the above?: well you can do it on your own with the help of a script from within (c)VMWare Tools. This script will handle three events: freeze, thaw and freezefail Windows batch version: Create the dir: "C:\Program Files\VMware\VMware Tools\backupScripts.d" Create some file inside of it and run the code below adapted to your own DB system, we are using some code suitable to be used with MariaDB or MySQL. The scripts in the above dir will be run in alphabetical order. FREEZE is the event that will be run just before taking the snapshot THAW is the event that will be run when finishing to take the snapshot FREEZEFAIL is the event that will be run when the snapshot fails to be taken.
@echo off
if "%~1" == "" goto USAGE
if %1 == freeze goto FREEZE
if %1 == freezeFail goto FREEZEFAIL
if %1 == thaw goto THAW
:USAGE
echo "Usage: %~nx0 [ freeze | freezeFail | thaw ]"
goto END
:FREEZE
set PATH=C:\Program Files\MariaDB 10.6\bin\
mysql -uroot -p"yourpassword" -e "FLUSH TABLES WITH READ LOCK;SET GLOBAL read_only = 1;"
goto END
:FREEZEFAIL
set PATH=C:\Program Files\MariaDB 10.6\bin\
mysql -uroot -p"yourpassword" -e "SET GLOBAL read_only = 0;UNLOCK TABLES;"
goto END
:THAW
set PATH=C:\Program Files\MariaDB 10.6\bin\
mysql -uroot -p"yourpassword" -e "SET GLOBAL read_only = 0;UNLOCK TABLES;"
goto END
:END
What the script does is the same we have explained above in a dialectic manner. There exist some wrapper SQL commands like FLUSH TABLES FOR EXPORT that will basically join the FLUSH and SET to read only operations. Nonetheless we have kept the two commands differentiated so that you can understand better what the script does. Linux bash version: Create directory: /etc/vmware-tools/backupScripts.d The backupScripts.d directory may contain one or multiple scripts that will be executed in sequence. The file names of the scripts affect the execution order (e.g. 10-application.sh, then 20-database.sh). Each script must be able to handle freeze, freezeFail and thaw arguments passed by the VMware Tools during the different phases. Make sure the scripts are executable (permissions, correct type for the VM operating system). Script below:
#!/bin/bash
if [[ $1 == "freeze" ]]
then
echo "This section is executed before the Snapshot is created"
elif [[ $1 == "freezeFail" ]]
then
echo "This section is executed when a problem occurs during snapshot creation and cleanup is needed since thaw is not executed"
elif [[ $1 == "thaw" ]]
then
echo "This section is executed when the Snapshot is removed"
else
echo "Usage: `/bin/basename $0` [ freeze | freezeFail | thaw ]"
exit 1
fi
Daniel J. García Fidalgo 33HOPS |


|