



|
Last updated on Friday 11th of August 2023 04:17:28 PM Free ©VMWare ©ESXi backup & replicationCompatible with ©ESXi Free from 5.5 to 8.0. Deduplication, zero aware, perpetual license, Changed Block Tracking, differential, IP backups via SSH, unlimited restore points, cloud backup.You can use your keys at either the ©XSIBackup service running in the ©ESXi Hypervisor or at
the ©XSIBackup-App appliance, able to connect and manage multiple servers.
Now with 21 months of free updates!
(*) ©ESXi 8.0 compatibility is offered since v. 1.6.0.11 all in editions: Free, Pro, DC & App appliance. (**) ©XSIBackup does not support hot backup of datastores extended over multiple physical disks. (***) ©XSIBackup-Free is the trial version for all editions. Looking for ©XSIBackup Classic?: click here Description©XSIBackup turns any free or licensed ©ESXi server into a full fledged virtualization system by adding live replication and backup of Virtual Machines and the host's configuration.Copy data locally or over IP to any ©ESXi or Linux system or to a deduplicated backup repository yielding up to 99% compression ratio with a differential delta checksum or CBT Changed Block Tracking technology (only DC edition). It has a built in block level deduplication engine. It can deduplicate data to any file system that you can mount over NFS or connect to over SSH. It needs nothing else to do it. It incorporates advanced indexing algorithms that allows it to find a block in a multi-terabyte VM in microseconds and does it at a sustained rate. It uses little resources on your ©ESXi host, thus you can use it to backup your guest virtual machines while you use them without even noticing the load. ©XSIBackup is an extremely resilient piece of software, designed for professional system administrators that prefer reliable command line tools to fancy colourful windows. Our software is used by renowned enterprises and public institutions in five continents. It offers features that differentiate it from all the other available solutions. It works both backing up data to local resources or over IP. This makes it the ideal tool to protect from new ©ESXi Ransomware, as you can keep your backup sets in some remote backup server authenticated through a private key, making it easier to protect and keeping backups in an isolated zone. We offer a fully enabled trial version that you can use to try out all features until the trial period expires. Then you can still use it to backup virtual machines up to 100 GB in size to local datastores. An nCurses GUI allows to quickly deploy backup and replication jobs as well as to test SMTP servers and run the jobs manually.
©VMWare ©ESXi Enterprise Ready Backup solutionsOur software has been tested and refined along more than 10 years, both conceptually and empirically. It's just reliable and obsessively optimized to employ the least possible resources. ©XSIBackup simply enables deduplicated backups, unlimited restore points, instant differential backup/replica and granular restore for all your ©ESXi servers without having to spend any additional amount on hardware. It allows you to perform the backups to any local or IP volume over SSH, this way you can take advantage of any preexisting system. You only need a backup volume which is about the same size than your VMs to be able to host dozens of restore points for archival 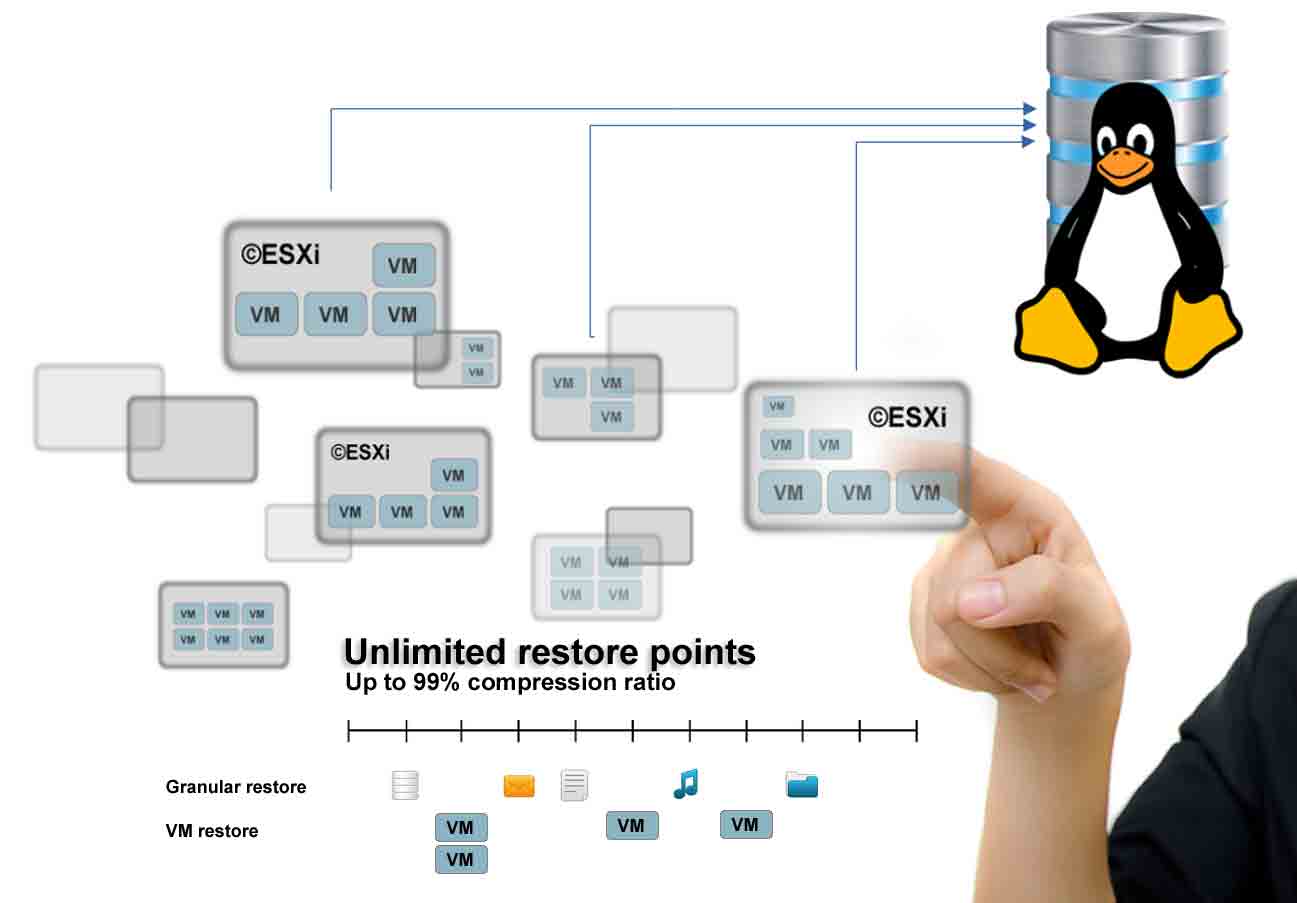
©XSIBackup takes advantage of ©VMWare's CBT (Changed Block Tracking) technology to just copy the blocks that have changed since the last iteration, both for backups and replicas. It is zero aware, so that you just use the space you need and don't waste your valuable resources accumulating zeroed space. It will even detect the zeroed zones that have not been reclaimed by VMFS to avoid wasting space. You can in turn easily replicate your generated repositories over IP to have offsite copies with maximum efficiency. In short, ©XSIBackup is an extremely cost efficient tool that will not only protect your data from increasing threats like Ransomware or ordinary Viruses and Trojans, but will increase your IT department's intrinsic value by saving you time and offering you the confidence you need to know that you'll be protected from whatever comes your way. One year of supportWhen you buy your license you have one (1) year of support. This includes help in installing and configuring your backup jobs. We have published posts and tutorials on the most common subjects and situations, thus we may redirect you to the documents. In case your issue is not a recurring one we will help you to fix it and to deploy your best possible backup and replication strategy. Should the case can be helpful to others we may publish an anonymized post on the subject. This doesn't mean that we will offer you free consultancy, but that we will point you in the right direction and offer you clues to achieve your goals. If you want consultancy we can offer it to you at very competitive prices as published in our Remote Support information page. |


|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Download:
Download: 
 Download
Download Add to cart:
Add to cart:  E-mail helpdesk
E-mail helpdesk