
|
Last updated on Monday 28th of February 2022 08:52:48 PM ©XSIBackup-Pro Classic: two step deduplicationHow de-duplication block size affects backup performance and how to use the available tools to maximize backup performance and space utilization Please note that this post is relative to old deprecated software ©XSIBackup-Classic. Some facts herein contained may still be applicable to more recent versions though. Please note that this post is relative to old deprecated software ©XSIBackup-Classic. Some facts herein contained may still be applicable to more recent versions though.
For new instalations please use new ©XSIBackup which is far more advanced than ©XSIBackup-Classic. Read next post: Deployment of a two step deduplication system When it comes to take advantage of your backup space (always limited), deduplication becomes a great technology to use in conjunction with your favourite backup hardware: hard disk, NAS, tape, or whatever you like the best. Please, note that although you can store deduplicated repositories into tapes, you will first need to copy them to a hard disk to be able to extract its contents, as tape devices have sequential access to data. Deduplication is great, no doubt about that, but, we already mentioned that it does have some constraints vs backing up data regularly. In this post, we posed some of the facts. 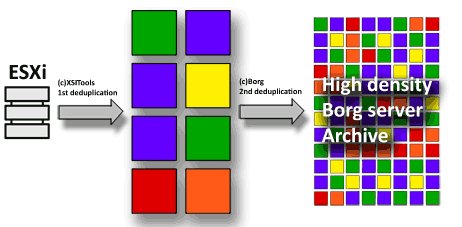 The thing is that, the smaller the block size is, the biggest the compression ratio will be.
You might think "great!, let's use the smallest block size possible". But, as everything in
life, every advantage claims a trade off and very seldomly good things are not followed closely
by some downside. As in every other applied science scenario, we are bound by the limits of physics,
or to be more precise, we are limited by the speed of our CPU and memory and also the size of the
latter.
The thing is that, the smaller the block size is, the biggest the compression ratio will be.
You might think "great!, let's use the smallest block size possible". But, as everything in
life, every advantage claims a trade off and very seldomly good things are not followed closely
by some downside. As in every other applied science scenario, we are bound by the limits of physics,
or to be more precise, we are limited by the speed of our CPU and memory and also the size of the
latter.
You probably already know what deduplication is and how it allows to save space in your backup disks. Deduplication is, in a nutshell, a way to split data into chunks (blocks) and save each one of them only once. The original data can then be reconstructed by using a pointer to a given block there were it existed. To rebuild the original data you just have to follow each pointer, grab the associated data and stick blocks together in the same order indicated by the pointers. We use the word pointer here as a mere way to indicate some mechanism that refers to the block uniquely, like its hash, which is conveniently stored in a file containing the virtual disk definition. That file will be invoked when you need to restore the backup, and blocks will be repositioned in a binary file which will be an exact copy of the original. The problem when you slice the original data into small chunks is that you end up with a huge list of hashes or pointers. Traversing those logs in search of each unique hash can be very exigent with your CPU once you have reach some millions of pieces. Not to say memory utilization grows wild, as OSs tend to cache everything they can into memory when performing exigent operations, to obviously maximize performance, as RAM is still much faster than HDs. By using SSDs things improve significantly, but still you count with limited resources. So using a small block size can clog your server while the deduplicated backups are taking place. So, what can we do to minimize block size impact?, guess what...: increase the block size, yeap!. That measure alone will free your resources from an excessive load. Before we go on, we must place two facts on top of the table: first, we are talking in relative terms, obviously the amount of resources you have will determine the outcome of that excessive load we are talking about. Nevertheless, resources are always expensive and over utilized, and it does not matter which are the absolute figures, when it comes to CPU and RAM, you will always be short of them. Using a 16 kb block size vs. 50M as XSITools uses by default, in an average SME virtualization server, is the difference between users complaining and things going sloooow or not even noticing that a backup is being done in the background. Second fact is that, as we are storing each unique block of data just once, we are reading all data, as we need to get each block's checksum, but we are writing only new blocks, so I/O is greatly reduced in comparison to performing a regular backup, where all data is copied every time. XSITools technology is the result of analyzing how VM hard disks are compounded from a data block perspective and increasing block size of the deduplication process until getting a more than decent data storage density while reducing overhead to almost nothing. What do I mean by "decent data density"; well we all know that compressing binary data can reach a 50% compression ratio at most as an average. When using XSITools with a 50M block size, you can easily multiply by 30 or 40 times your space utilization, which is well over 95% compression ratio, in some cases even more. I believe this is very interesting for any sysadmin or IT specialist. You can achieve a huge space utilization ratio while keeping your servers calm and reducing data writes to minimum. But you still could reduce the size of your backups if you used a smaller block size, especially since we recommend to rotate XSITools backups every month, or even better, use two XSITools repositories: one for even days and a second one for odd days. This is to reduce the chance of loosing individual blocks due to hardware flaws or data corruption and to limit the number of blocks stored per repository which will keep XSITools rocket fast. Here is where our favourite general purpose deduplication tool comes into play: ©Borg. As you most probably already know, ©XSIBackup Classic offers the possibility to store your backups in a ©Borg server. In any case Borg's strengths are also its weaknesses; as it has been designed as a general purpose archiving tool, it uses a small block size to minimize space utilization, which does very well, but as you add terabytes of data, it starts to slow down. This will of course be relative to your available CPU and RAM, but still, even very powerful servers will end up clogging under a heavy load. That's why we created XSITools, we needed some lightweight deduplication tool that would be designed to store virtual disks data chunks. We are going to utilize an average scenario to pose our proposal in regards to Two Step Deduplication. That is an ESXi server with 700 gb. of data in VMs comprising both Windows and Linux OSs. Of course, the first step in reference to the post's title would be the XSITools repository. The second level or step would correspond to our Borg Backup repository. So the idea is that once we have completed an XSITools backup, we can archive the resulting data into a ©Borg server, reducing the size of it to the minimum possible while enjoying at the same time the benefits of a lightweight block deduplication tool for the first stage. By using this approach, you can have a first level deduplicated repository, which would allow you to store one or two months of VM data and that would easily allow you to restore any version of a Virtual Machine in that time frame, plus a highly compressed ©Borg repository, that would allow you to go back in time, even years, with a relatively small backup storage capacity. How do you translate that to figures?, well that will depend very much on the kind of OSs you use, how much new data you generate every day, and a lot more circumstances, but I could fairly say being realistic, that a 2 tb. hard disk should allow you to store two months of a VM set of about 700 gb., and that around 4 tb. capacity at your Borg server would allow you to store more than one year of Virtual Machine backups. You could probably do it even with less than those 4 tb, depending on the amount of new unique data you generate. Any Linux distro that can run ©Borg and act as an NFS 3 server will do it as the storage server for the first step backups, that is, where to store the XSITools repositories. From there, you just need to program a Borg backup in your Linux crontab to archive your data to a ©Borg server, enjoying small block deduplication and differential backup. This last stage is then ideal to keep your Borg archive off-site, in a dedicated server or in an alternate site. Read next post: Deployment of a two step deduplication system Daniel J. García Fidalgo |


|
Login • Available in: 