

©XSIBackup Datacenter: pruning old backups
What is pruning and how does it work
Although from a user's conceptual point of view pruning blocks from old backups, that is: getting rid of some old unwanted backup and its exclusively associated blocks, may be considered a trivial matter, it is not. It is indeed quite an exigent task, both in hardware terms and also requires some good amount of skills from part of the programmer.
To find out why we should think a bit about what pruning is and what are the tasks that need to be run in the backup server for pruning to be possible.
A de-duplicated backup is nothing but a set of chunks coming from some sliced bigger files and the data definitions of the original files being backed up. The data definitions in case of ©XSIBackup-DC are some .map files which are stored in the timestamped folders and its subfolders generated on each backup cycle.
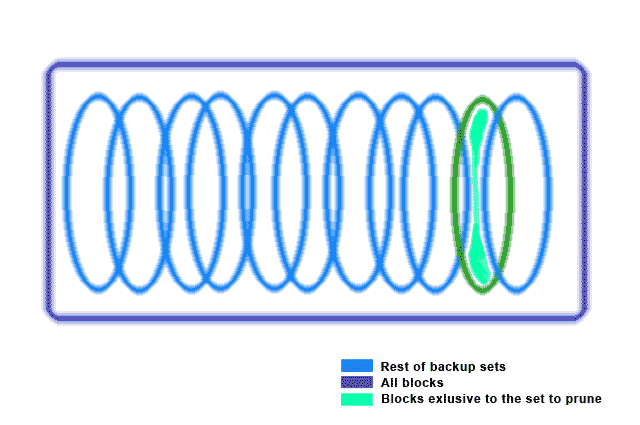
(*) The above image does not pretend to be an accurate graphical representation of the existing relationship among the blocks in the repository but just some visual hint on that matter.
To correctly identify the blocks to prune when deleting some older backup folder, we need to find out which blocks among all those that compose the files being contained in the whole backup set are used exclusively by that backup that we want to delete.
And this is where the risks of pruning come from: we will keep blocks that we can find among the other set, failing to find a block among the other backup sets can cause unwanted block deletion. Thus, we'd better make sure that we collect all the blocks in the other backup sets and that we thoroughly look for each of the blocks there.
This is why ensuring there is enough space for pruning is essential, as a partial log will inevitably lead to a disaster. Since version 1.1.0.8 additional re-checks are performed to make sure the general block log is indeed generated and that all blocks match. This takes some extra time, but it's little and worth spending.
The only way to know that is to compare the set of blocks in all the other backup sets, the ones that we want to keep, with the blocks in the backup set to delete. Those blocks that we are not able to find in the other backup sets are those that are exclusive to the data being pruned and therefore, the ones that should be deleted from the block database.
Although we just record a 40 bytes string for each block of data in the data definition files (.map files), plus the size of the chunk plus a line feed character, this files can become quite big when we use the smaller block size of 1M. We accumulate 42KB of data per gigabyte in each file being backed up, and that information repeats in every backup's set of .map files, so just keeping 60 restore points for a relatively small set of virtual machines can become quite lengthy, in the order of hundreds of megabytes. This isn't much for modern servers, but still requires to make some tweaks to the OS holding the data.
The place where all the files implied in the pruning process are stored temporarily and where they are compared is the /tmp folder of your OS. This is a good idea, as most modern Linux systems mount this TMP file system in RAM and this makes working with files inside this folder faster than doing it in a regular file system stored in an HD.
In any case many Linux FSs configure a pretty small /tmp file system for modern standards. In fact ©ESXi's /tmp file system is limited to 100MB. This is one of the reasons why you shouldn't store small block ©XSIBackup-DC repositories directly in VMFS. ©XSIBackup-Pro did use VMFS to store deduplicated backups, but it's smaller block size was 10MB and the default and most commonly used block size is 50MB, so you needed ten times less space to calculate blocks to prune in case of 10MB blocks and 50 times less in case of 50MB blocks when compared with the smallest possible block size in ©XSIBackup-DC (1MB).
So, first thing to do in a Linux box or appliance you are using as your ©XSIBackup-Datacenter server is to make sure you have enough /tmp room to perform all the pruning operations. That will mainly depend on the number of restore points you are planning to keep. You can calculate that by applying the following formula:
[Number of GB per backup]*41*[Number of restore points]/1024/[Block size in MB]
Always leave some 20% extra room to store some extra temp files which are created during the pruning process. The above will tell you the number of available MB in your /tmp file system you need to prune your VM set. That is roughly around 4MB per each 100GB of data per restore point when using a 1MB block size. So, to store 100 restore points for a 500GB set of VMs you would need a TMP file system with at least 2GB available, which will probably exceed the default size of your Linux /tmp FS.
Fortunately increasing the size of a /tmp file system in a linux OS is fairly simple, just run this command:
mount -o remount,size=2G /tmp/
The above command should work on Linux systems that have a mounted /tmp partition in the /etc/fstab file. Some OSs keep the /tmp folder in one of the mayor partitions, in those cases you will not be limited by the /tmp FS size.
In case of employing a 10MB block size, your need for space and CPU will drop by a factor of 10. Bigger block sizes will make the need for space vanish, as even with a high number of restore points the figures will remain very discrete.
What to keep in mind when pruning backup sets
Keeping the above information in mind is fundamental at the time to design your backup topologies with ©XSIBackup-DC. First of all you have to decide which is the best block size for your requirements. A smaller block size will help save more space while at the same time will make it faster to backup your VMs over a narrower link. The differential data will be smaller and faster to transfer to a cloud server per instance.
A bigger block size like 10MB will still offer you a huge compression ratio and will have the advantage to keep all logs: .map files, .blocklog and prune logs small, so it will be easy and fast to add and remove blocks.
What you should not do
If you plan to take advantage of your available backup space as much as possible and you want to keep many restore points, let's say 200 of them, you may decide to use a 1MB block size and that will be fine. You will be able to backup and restore VMs nimbly while keeping the maximum possible compression ratio, in case of such scenario you would most probably be well over 98% compression ratio.
Nonetheless trying to combine a --rotate=200 strategy to liberate space for newer backups when you reach the 201 cycle might not be a good idea. You would be generating in that case around 3.2 GB of block logs for a 400 GB Virtual Machine data set or 6.4GB for an 800GB one. You would need to traverse that data many times to get rid of the blocks to prune and that could take hours after each backup cycle.
When you design a long term (many restore points) small block size strategy, you usually do that to keep a historical recoverable state of your VMs. You will normally want to keep that data safe in a yearly archive, thus trying to rotate such a big backup set would be unwise.
You could very well achieve optimum rotation results with a 1MB block size and 10 restore points, the backup repository would then be easily pruned in a matter of 3-5 minutes, or in a couple of seconds should you decide to use a 10MB block size.
Important facts
From ©XSIBackup-DC 1.0.1.0 the main tmp dir used to store the prune logs will be moved to the installation dir root. The recommended installation dir is /scratch/xsi, thus the new location for the prune dir will be /scratch/xsi/tmp.
The /scratch partition has a default size of 4GB which is more than enough to handle prune logs for multi TB backup sets including many restore points. Nonetheless, in case of facing extremely exigent projects, you should move your scratch dir location to a datastore with enough space, a perfect place would be your SSD cache disk.
To move your /scratch dir symlink to a new location, just create a new dir in the new desired location, i.e.: /vmfs/volumes/datastore1/scratch
mkdir /vmfs/volumes/datastore1/scratch
The use this command to change the location in the ESXi configuration and reboot your server.
vim-cmd hostsvc/advopt/update ScratchConfig.ConfiguredScratchLocation string /vmfs/volumes/datastore1/scratch
You may as well need to move your xsi dir to the new location
mv /vmfs/volumes/old-scratch-volume/xsi /vmfs/volumes/datastore1/scratch
Daniel J. García Fidalgo
33HOPS

