
|
Last updated on Sunday 22nd of May 2022 12:15:36 PM ©XSITools: ©VMWare ©ESXi block level deduplication Please note that this post is relative to old deprecated software ©XSIBackup-Classic. Some facts herein contained may still be applicable to more recent versions though. Please note that this post is relative to old deprecated software ©XSIBackup-Classic. Some facts herein contained may still be applicable to more recent versions though.
For new instalations please use new ©XSIBackup which is far more advanced than ©XSIBackup-Classic. Update 2021-05-23: ©XSIBackup-Pro Classic, our former line of software for ©ESXi VM backup, used a bash based deduplication engine which would make use of dd to slice the data chunks and store them in the deduplicated database of data chunks. It used a default block size of 50MB, which still yielded a more than decent compression ratio on the VM data. Some people used VMFS to store the deduplicated data on secondary disks attached to the host or in iSCSI/FO datastores. VMFS is a slow FS, still, as the blocks were pretty big, this wouldn't affect the backup speed much. Now ©XSIBackup-DC, our latest software, which is more advanced and it's faster than ©XSIBackup-Pro Classic uses a 1MB block size, which allows better optimization and speed. Nonetheless, VMFS is not a good FS to store deduplicated backups any more due to a reduced default block size of 1MB, as the speed that VMFS6 yields does affect the empiric backup figures. VMFS5 offers only 130,000 inodes. In case of 50MB blocks you could still fit some good amount of deduplicated data in a VMFS5 volume, it's nonetheless useless to store 1MB block size repositories. In case of VMFS6, it can store millions of files, yet, as explained above it's very slow when compared to ext4 or XFS. Thus, use some fast file system in an NFS datastore to accumulate your deduplicated data.  Needless to say using some heavy duty FS on an underdimensioned NAS device can slow your backups down to
whatever extent you desire. To pose an analogism: you don't compress your data 7 times, most of us know that once you have compressed some data using some
compression utility, you won't achieve any further compression by recompressing it over and over. Needless to say using some heavy duty FS on an underdimensioned NAS device can slow your backups down to
whatever extent you desire. To pose an analogism: you don't compress your data 7 times, most of us know that once you have compressed some data using some
compression utility, you won't achieve any further compression by recompressing it over and over.
The same applies to deduplication, yet; as it's even more exigent than mere compression, applying redundancy to your system may render it unusable. Per intance, we found some users are trying to replicate and backup in real time to some BTRFS or ZFS FSs with deduplication enabled. If you happen to do that on some well dimensioned server, you will be wasting your money, still your backups will take place. But if you try to do the same in some NAS device with little memory and a not very powerful CPU, you will just clog your NAS device. Please always use real fast file systems to store deduplicated data. In case of replicas you have more freedom to experiment, still don't do crazy redundant things in production if you care for your data. Update 2020-11-26: ©XSIBackup-DC has superseded ©XSIBackup-Pro. It is faster, It offers much better figures in all aspects and its 1MB default block size produces more compact repositories. Update 2019-07-04: In the last versions ©XSITools has experimented some improvements that make it more reliable and certainly much faster than in previous ©XSIBackup-Pro Classic versions: 1 - Zero zone awareness: since v. 11.0.0 ©XSITools algorithm will jump over VMFS zones which don't contain any data. This dramatically improves the speed of backups, especially in disks that contain little data in comparison with the full expanded disk size. Before this improvement, each block of data had to be checked against its hash to verify whether all bytes were zero. In case you store your disks in a non-VMFS volume, no zero jumping will occur and each block will still have to be checked. ©XSITools is introduced as a new feature in XSIBackup-Pro 9.0. It will first offer block de-duplication over VMFS and any other proper file system like: ext3, ext4, XFS, NTFS, FAT32. etc..., that allows to store some tenths of thousands of files per volume. As it evolves it will offer block synchronization for off site backups. VMFS 5 storage limits and XSITools According to VMWare's documents: vSphere 5.5 Configuration Maximums A VMFS5 volume can store up to 130,690 files. That number should include dirs too. This means that, making some quick figures, if you have 130.000 free inodes for block storage and each block is 50 mb. big, you could host up to 6.5 tb. of real data in chunks. That could easily range from 30 to 70 tb. of deduplicated data, which is more than enough to consider XSITools repositories as a serious backup storage engine. You can obviously have one or more XSITools repos per volume, so you can easily grow your backup space by adding more disks, or by splitting disks into smaller volumes. Other FS available through NFS/iSCSI/FC The above paragraph has to do with VMFS file systems, or in a more plain language, hard disks that are directly connected to our host controller and formatted by using this VMWare propietary FS. VMFS was designed to host VMs, not to store a pile of smaller chunks of data, that's why their designers weren't thinking about hosting de-duplicated data. In any case, most of the times, the storage we will be using is an external NAS connected via NFS/iSCSI/FC, therefore those datastores will sometimes be formatted under a different FS: ext3, ext4, BTRFS, XFS, NTFS, FAT32, etc... With most of the above mentioned file systems, the availability of inodes (number of files, dirs, symlinks ...) is in the order of millions, so you can make some quick figures on your own to realize that you'll never have to worry about the limit of deduplicated blocks you'll be able to host. There will nevertheless exist fundamental differences between those file systems in speed and reliability. Although you may be able to host deduplicated data in a FAT32 File System, in the long run it will end up causing you some trouble. You need some file system which is both fast, reliable and resilient to failure. Our favourite FS to store chunks of deduplicated data for the time being is EXT4 without doubt. XSF which has been adopted as the default FS by some new Linux distros is great too. Ext4 still beats it at the time to handle many small files. To delve into this topic you can start here: •Comparison of File Systems •ext4 File System Please, avoid FUSE filesystems to host deduplicated data, they are very sloooow. They might make sense to have data distributed among different servers or to make use of inline deduplication, but to host XSITools repositories you need a real filesystem. You may achieve good results by combining high end CPUs with fast SSDs, nevertheless, please: follow our advice in regards to how to use deduplication or understand it and weigh your requirements adequately. XSITools over IP Since version 11.1.0 ©XSITools allows to copy data over IP to a remote ESXi server or to a Linux server. We use CentOS as our reference distro, that will offer you tested compatibility with CentOS, RHEL and Fedora distributions. Since WAN connections aren't as fast as LANs, almost but not yet, and certainly not all. Using a big block size such as the default ©XSITools block size, which is 50M, might not be the best idea. ©XSIBackup allows the additional argument --block-size=[50M|20M|10M] when combined with ©XSITools only. This will change the size of the block size used by ©XSITools. The number of blocks will be higher, but the amount of redundant data sent to the other end will be dramatically reduced too. General considerations XSITools uses block level de-duplication with a big block size, 50 mb. by default. We might offer adjustable granularity in the future to better control off site backup data block outer flux. Some of you who are already familiarized with de-duplication at the FS layer might be thinking: "this guys have gone crazy, how come they use a 50 mb. block size to de-duplicate data". Well, the answer is simple, because it's more efficient. It's not more efficient if you consider minimizing disk space by applying de-duplication as the only goal. It is more efficient when dealing with a wider scope goal: backing up a fixed set of production virtual machines by using the least resources possible, while still maintaining the benefits of using deduplication to achieve a high data density ratio. Block de-duplication is a must when recursively backing up virtual disks, but using a small block size makes no sense in this context. De-duplication offers the big advantage of storing data chunks uniquely, it is a simple and brilliant idea from a conceptual point of view. It only has one disadvantage, it is resource hungry, it is so CPU and memory intensive that when it comes to backing up terabyte files you might end up needing extremely powerful (and therefore expensive) servers to handle zillions of tiny chunks of data. A fixed set of virtual machines in production constitutes a set of big files that will only experiment limited changes from one backup cycle to the next. It is database and user files that will get changed from one day to the next. Still, most of those files will remain unchanged, as well as the vast majority of the OS constituent parts, that will as well, remain aligned to the previous day version in terms of data structure. 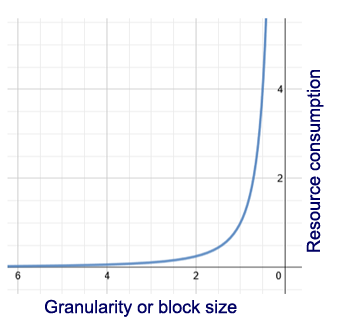 Engineers' task is not to build perfect solutions, perfection is a job for mathematicians, engineers must offer
reasonable and practical solutions to every day's problems. Thus, as a software designer, I don't care much to
copy 50 mb. of data when only one byte has changed in the extent, if as a counter objective I am saving
99% of the CPU time and freeing the memory from a huge data storm that would freeze my server. There's a thin
line that depicts the optimum trade-off path that we must follow to accomplish our task with the minimum set of
resources. As mentioned throughout my posts, there must always be a philosophy behind every complex tool, as
stated before, I'll follow the market trader quote "let others win the last dollar".
Engineers' task is not to build perfect solutions, perfection is a job for mathematicians, engineers must offer
reasonable and practical solutions to every day's problems. Thus, as a software designer, I don't care much to
copy 50 mb. of data when only one byte has changed in the extent, if as a counter objective I am saving
99% of the CPU time and freeing the memory from a huge data storm that would freeze my server. There's a thin
line that depicts the optimum trade-off path that we must follow to accomplish our task with the minimum set of
resources. As mentioned throughout my posts, there must always be a philosophy behind every complex tool, as
stated before, I'll follow the market trader quote "let others win the last dollar".
The difference in resource consumption between using a big or tiny block size consists mainly in CPU time, used to locate the chunk of data in a file system or key/value database. By using a big block size, we sacrifice data density in sake of freeing the CPU from that task, and the result is worth the saved CPU. Data density still keeps high, although it obviously drops, and CPU utilization is so low that you can use your servers while they are being backed up, without noticing much interference from part of the backup process. So, as an excerpt: XSITools uses a big block size, because the resources needed to copy 50 mb. are much more limited than those required to de-duplicate 12800 4k blocks, and the disadvantage derived from using a big block size is an increment in the real space used by deduplicated data. Still a big space saving ratio is reached while enjoying the benefits of a lightweight de-duplication engine, that will use very little CPU time, leaving it available to the running VMs. The above is valid when dealing with a local scenario: local storage pools or NAS in a gigabyte or 10gb. LAN. When we need to replicate data across "not so wide" networks, like WANs, things start to change. In this case, the most valuable resource might be our Internet bandwith, and in this new circumstances, we might do well by "winning" even the last dollar available. For this especial type of scenario we will evaluate the possibility to offer smaller block sizes. XSITools also offers since v. 9.1.2 block compression via LZO, which ensures a good compression ratio while keeping the same absolute speed figures. Understanding XSITools How does XSITools work?, well, you can have the details by just inspecting the source code. We will explain the way it works, it's strengths and weaker points from a conceptual point of view. What XSIBackup does is to slice the backed up files using a big block size (50 mb. is default), it calculates each slice's SHA1 hash and names each one of this slices or packets of data using the obtained hash. It optionally compresses each one of these blocks of data using the LZO compression algorithm, which is fast enough for the compression phase not adding extra time to the deduplication backup process. XSITools only deduplicates -flat.vmdk disks, the rest of the files are backed up by just copying them to their corresponding repo folder. Therefore, only the -flat.vmdk files inside the repo are actually hash tables, the rest of the files are just copies of their original counterparts. Each VM is comprised by an integer number of blocks which is obtained by dividing the full .vmdk disk size by the block size. If the division does not throw an integer, XSIBackup rounds to the next integer value, considering that last chunk of data a full block in size to host all those left bytes. This is what you will see expressed as "Block count" when performing an XSITools backup. Out of those count blocks that comprise the VM, not all will be backed up. Many of them will be zero blocks, they will be skipped when they are detected. Thus, the real number of blocks that will be backed up in a first backup of a .vmdk disk, will be the non-empty blocks present on the file. On subsequent backups, many of the hashed blocks will already exist in the XSITools repository, hence they will not be copied, as they are already present, this will save valuable time when making the backup, as only the time to get the hash value plus the time taken to look for the block in the FS will be required, in contrast to having to copy all 50 Mb. each time. From a space saving perspective, only the changed blocks will be actually backed up on each subsequent backup cycle, making XSITools repositories achieve a high level of density. To use XSITools just parse the xsitools value to the --backup-prog argument. If an XSITools repository is not already present at the provided path, the folder will be created and the repository will be automatically initialized. You can optionally parse the --check-repo=yes argument, to check the repo once the backup has finished.
./xsibackup --backup-prog=xsitools --backup-point="/vmfs/volumes/backup/$(date +%Y%m)-xsitools" --backup-type=custom --backup-vms=MyVM1,Linux2,Windows3 --mail-to=you@yourdomain.com --use-smtp=1 --check-repo=yes
Used arguments: --backup-prog=xsitools --check-repo=yes Downsides of block level de-duplication As commented in our series of posts titled "XSIBackup-Pro Out of the Box", block level deduplication has a big advantage, which is to save space, as unique pieces of data are kept just once on disk. But its power is its weakness at the same time, as losing a single block of data could lead to multiple files being unrecoverable, if that block is shared by those files. Alternating different repositories for backup, ideally located in different backup devices or hard disks is the best approach. You can check repositories and just archive them from time to time, taking advantage of an extreme level of data density. In fact, by combining two backup devices with an additional full backup per week, you are well covered from most possible incidents: hardware failure, viruses and ransomware, accidental deletion, etc... XSITools is a very robust mechanism, despite being a script, in any case it produces a high traffic load between the ESXi OS and the storage device. We use to not recommend async NFS here, but if your network and NAS device are reliable, the chances that you lose data are very small. Nevertheless, we provide post backup verification tools (--check-repo argument), that can check that every individual chunk of data's hash is correct. Checking data consistency Before starting to comment on this topic, we must say that XSITools is a quite mature tool used by many people. It is efficient, fast and reliable, so you should not need to use the information below, unless you depend on aged hardware, specially hard disks, which is a common issue in many small SMEs nowadays. The chances that you loose one block of data are relative to the age of your hardware. In case you need to deal with data loss, comprehending how ©XSITools works may "save your life". Blocks are sliced using dd, hashed via OpenSSL and compressed using the LZO binary present at ESXi, this last phase is optional, although its usage is highly recommended. In fact speed figures are, at least, as good as the ones you will get without compression enabled. So, always add the :z argument to the XSITools program, like this: --backup-prog=xsitools:z. XSIBackup provides two ways you can check data consistency: 1 - Full repository check: this type of check will count all physical blocks present at a given repository and calculate their hash again to make sure it matches their name (remember we name blocks after their SHA-1 hash). 2 - Individual VM version check. To perform this type of check, you just have to parse the path to a specific copy of a VM inside the repository, something like:
./xsibackup --check-xsitoolsrepo=/vmfs/volumes/backup3/201704-xsit-50MZ/20170403001001/MyVM --mail-to
Used arguments: --check-xsitoolsrepo --mail-to This will check every block in the .vmdk hash tables for every -flat.vmdk disk in the VM. If you have additional snapshots, because you backed up a VM that already contained a snapshot, those files will not be checked. Only the base disks are checked. The same way as in the first case, every block in the hash tables will be compared with its current SHA-1 hash. A perfect check implies that the number of blocks present at the repository match the number of blocks registered at the .xsitools file in the root folder of the XSITools repository. But there could be two other non-ideal scenarios: one in which you have more blocks than actually registered at the .xsitools file. That would indicate that an XSITools backup process was interrupted before XSITools registered the copied blocks, so you have some orphan blocks. That won't cause much trouble, you could still add data to the repository and recover all VMs inside, except, of course, the one which backup process was interrupted. In case that you have less physical blocks than currently informed at the .xsitools file in the root folder of the XSITools repository, that can only mean that some blocks were deleted. That is a worse situation than the one commented previously, as you have lost data. In case this should happen, you can still use the repository, as the blocks that it contains will still be valid, but you won't know at first which VMs are lacking the missing/corrupt blocks. You could run a quick search in the VM folder hash tables, to find in which tables the missing blocks are present.
grep -r 5568496d349bf4fd5cd3003b4f4c6e96f29e3ca3 /vmfs/volumes/backup3/MyXSITools-repo/*/*/*-flat.vmdk
How to deal with bad/missing blocks This is highly unlikely to happen. Just as long as your hardware, cabling, setup, etc... are O.K.. Nevertheless, a good understanding of XSITools and its inner mechanisms can be acquired in a short period of time. If you detect a bad or missing block, there are two different strategies you can follow to fix your repository: you can first try to look for the block in another repository and use it to substitute the bad/missing block. If the block was unique, you might not be able to find it in other repos, in this case, your only option is deleting the bad/missing block(s) by using the --del-badblocks flag and running a new backup to try to recover the missing blocks from its source. If that piece of data has changed, you will get a newer working backup where that chuck was replaced by a different one, but you might never be able to recover the missing piece.
./xsibackup --checkxsitoolsrepo=/vmfs/volumes/backup3/201704-xsit-50MZ/20170403001001/MyVM --del-badblocks=yes
Used arguments: --del-badblocks Even if you find that you did lose a block. There are two possibilities: one, that your block belongs to a part of the OS that does not change much, like an older file, a system file or a program executable, in this case you should be able to find a healthy copy of it in other repositories; or two, that your block is unique, in this last case, the previous and following VM backups in the daily backup chain are likely to be healthy. |


|
Login • Available in: 